
We are starting a new series on the practical applications of data science in retail called, "Digital Commerce Data Mining". The first article in the series is 'Data Acquisition in Retail - Adaptive Data Collection'. Data acquisition at a large scale and at affordable costs is not possible manually. It is a rigorous process and it comes with its own challenges. To address these challenges, Intelligence Node’s analytics and data science team has developed strategies through advanced analytics and continuous R&D, which we will be discussing at length in this article.
An expert outlook on practical data science use cases in retail
Introduction
Intelligence Node has to crawl millions of web pages daily to provide its customers with real-time, high-velocity, and accurate data. But data acquisition at such a large scale and at affordable costs is not possible manually. It is a rigorous process and it comes with its own challenges. To address these challenges, Intelligence Node’s analytics and data science team has developed strategies through advanced analytics and continuous R&D.
In this part of the ‘Alpha Capture in Digital Commerce series’, we will explore the data acquisition challenges in retail and discuss data science applications to solve these challenges.
Adaptive Crawling for Data Acquisition
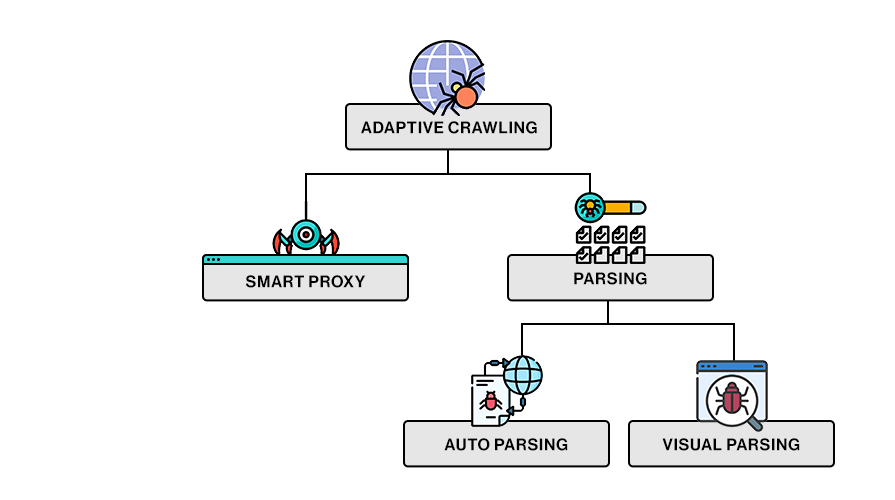
Adaptive crawling consists of 2 components:
The elegant middleware: Smart proxy
Intelligence Node’s team of data scientists has worked on developing intelligent, automated strategies to overcome crawling challenges such as high costs, labor intensiveness, and low success rates.
- Builds a recipe (plan) for the target from the available strategies
- Tries to minimize it based on:
- Price
- Success rate
- Speed
Some of the strategies are
- Election decision of a certain IP address pool
- By using mobile/residential IPs
- By using different user-agents
- With a custom developed browser (cluster)
- By sending special headers/cookies
- Using anti blocker [Anti-PerimeterX] strategies
The heavy lifting: Parsing
Auto Parsing
- The data acquisition team utilizes a custom-tuned transformer-encoder-based network (similar to BERT). This network converts webpages to text for information retrieval of generic information available on product pages such as price, title, description, and image URLs.
- The network is layout aware and utilizes CSS properties of elements to extract text representations of HTML without rendering it as opposed to the Selenium-based extraction method.
- The network can extract information from nested tables and complex textual structures. This is possible as the model understands both language and HTML DOM.
Visual Parsing
Another way of information extraction from web pages or PDFs/screenshots is through Visual Scraping. Often when crawling is not an option, the analytics and data science team uses a custom-built visual, AI-based crawling solution.
Details
- For external sources where crawling is not permissible, the team uses visual AI based crawling solution
- The team uses Object Detection using Yolo (CNN based) architecture to precisely identify product page into objects of interest. For example, title, price, information, and image area.
- The team sends pdfs/images/videos to get textual information by attaching OCR Network at the end of this hybrid architecture.
Example

Tech Stack
The team uses the below tech stack to build the anti-blocker technology widely used by Intelligence Node:
Linux (Ubuntu), a default choice for servers, acts as our base OS, helping us deploy our applications. We use Python to develop our ML model as it supports most of the libraries and is easy to use. Pytorch, an open source machine learning framework based on the torch library, is a preferred choice for research prototyping to model building and training. Although similar to TensorFlow, Pytorch is faster and is useful when developing models from scratch. We use FastAPI for API endpoints and for maintenance and service. FastAPI is a web framework that allows the model to be accessible from everywhere.
We Provide Sophisticated eCommerce Insights served via Scalable APIs, Custom Data Exports, & SaaS Portal : Learn More
We moved from Flask to FastAPI for its additional benefits. These benefits include simple syntax, extremely fast framework, asynchronous requests, better query handling, and world-class documentation. Lastly, Docker, a containerization platform, allows us to bundle all of the above into a container that can be deployed easily across different platforms and environments. Kubernetes allows us to automatically orchestrate, scale, and manage these containerized applications to handle the load on autopilot – if the load is heavy it scales up to handle the extra load and vice versa.
Conclusion
In the digital age of retail, giants like Amazon are leveraging advanced data analytics and pricing engines to review the prices of millions of products every few minutes. And to compete with this level of sophistication and offer competitive pricing, assortment, and personalized experiences to today’s comparison shoppers, AI-driven data analytics is a must. Data acquisition through competitor website crawling has no alternative. As the retail industry becomes more real-time and fierce, the velocity, variety, and volume of data will need to keep upgrading at the same rate. Through these data acquisition innovations developed by the team, Intelligence Node aims to constantly provide the most accurate and comprehensive data to its clients while also sharing its analytical abilities with data analytics enthusiasts everywhere.



